We will inform you about the milestones we have achieved in analyzing text reviews. Let’s take a look at our research.
Motivation
Our team is currently working on a project to help make decisions about buying different products. A huge amount of opinions and reviews of individual products can be found on the Internet.
These user reviews are distributed across a variety of discussion forums, product rating sites, or specific portals. For a regular user, it’s difficult to find the information needed, get a look at them, and make its own opinion.
Methodology
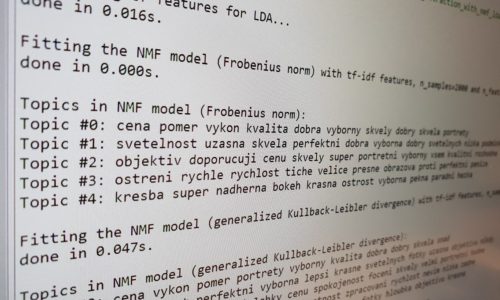
In order to analyze large amounts of unstructured data, we have decided to use machine learning methods. We want to use these data to identify topics that are important to users and to determine their positive or negative attitudes towards individual product features.
Current status
We are currently working on creating crawlers for downloading user reviews and articles about the selected product group. These crawlers are tailored to the structure of specific sites. Crawlers from these sites get relevant data that can help in analyzing themes and attitudes. So far, we have created eight crawlers, which have helped us to download about half a million user reviews and expert articles about two thousand products in two languages (Czech and English).
Problems solved
We had to deal with several issues when acquiring the data. One of the main ones is the different way of labeling products on different sites. Although it is an identical product, there are differences in names that complicate product pairing. Another problem is limiting the number of accesses to some sites in the form of code captcha. The last issue that needs to be solved is the changing web structure that causes crawlers to fail.
Conclusion
We have a practically closed first phase of the project in which we have defined the task of creating data acquisition tools for subsequent analysis. In the next phase, using machine learning methods, we will work to uncover the topics discussed and attitudes of users.
Jan Přichystal